HANCE 2.0: Realtime Stem Separation - Hello, Music Industry
HANCE Audio Engine v2.0.1 is now live - and with it, realtime stem separation made effortless.

Spectrogram-based methods for source separation using neural networks typically estimate a separation mask that is multiplied pointwise with the input magnitude spectrogram to form the separated output magnitude spectrogram. We have described these methods in our article Deep learning for audio applications.
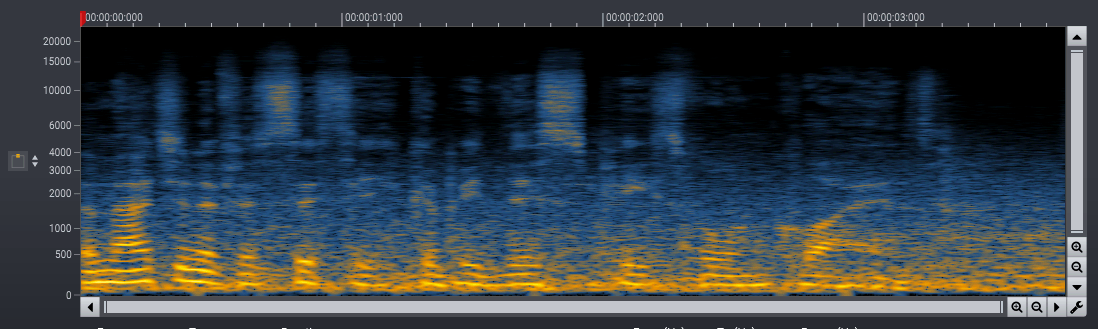
Traditionally, the mask consists of coefficients between zero and one. However, to reconstruct a signal from the magnitude spectrogram, the phase of each time-frequency component is required. Estimating the phase information is not trivial, and typically, the phase information from the input spectrogram is preserved. This constraint imposes an upper limit for the quality of the source separation which becomes evident when processing with the so called Ideal Real-valued Mask (IRM). The IRM can easily be calculated when the separated source signals are known in advance along with the signal mix used as input. Artifacts are quite noticeable even when using the IRM to separate the mixed input signal.
To overcome this limitation, the neural network for source separation should estimate both the output magnitudes and the phase information. Furthermore, the coefficients in the magnitude mask should be allowed to be greater than one, thus allowing the neural network to compensate for destructive interference that might have occurred when the source signals were mixed. For the mathematically interested reader, we can accomplish all of this by estimating mask coefficients that are so-called complex numbers. We will refer to neural networks that estimate the phase information as phase-aware processing.
Unfortunately, estimating the phase information is not trivial, and several different methods have been proposed in the scientific literature. To overcome the problems related to phase-aware processing with spectrogram-based methods, alternative methods such as TasNet and Conv-TasNet have been proposed. These use trained filterbanks to transform the signal to a custom representation (so called latent space) and back again. However, these methods do not guarantee an accurate reconstruction of the original signal.
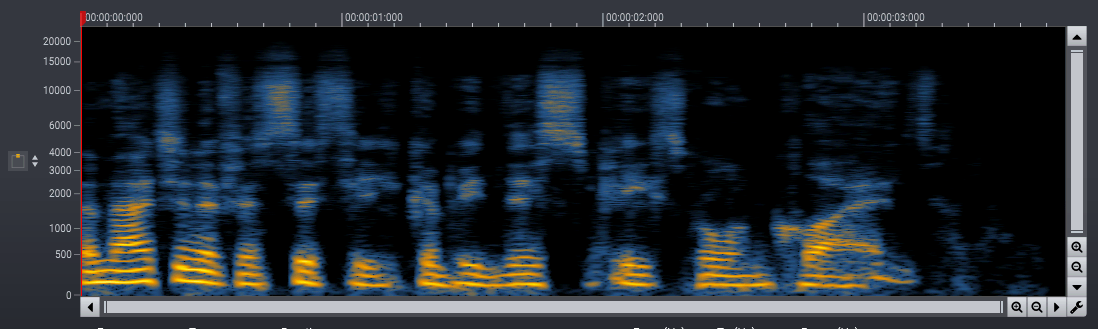
At HANCE, we have slightly modified the Short Time Fourier Transform (STFT) method that is used to calculate spectrograms to create a representation with both magnitude and phase information that is better suited for processing with Convolutional Neural Networks (CNNs). Our models for source separation estimate unbounded complex valued masking coefficients, that can correct both magnitude and phase distortions. Thus, there is no theoretical limit to the quality of the reconstructed signal.
We found that phase-aware processing significantly improves the perceived audio quality in low and mid-range frequency bands. For high frequency content, we found the differences to be neglectable. Since the phase-aware processing requires more memory and CPU, we trained hybrid models that use phase-aware processing up to 6 kHz and use pure magnitude processing in the 6 to 24 kHz frequency band (our models are trained on recordings with 48 kHz sampling rate). These optimizations make model inference using our HANCE Audio Engine very fast, and we achieve processing speeds higher than 26 times real-time with single-threaded processing on an AMD Ryzen 9 3950X.
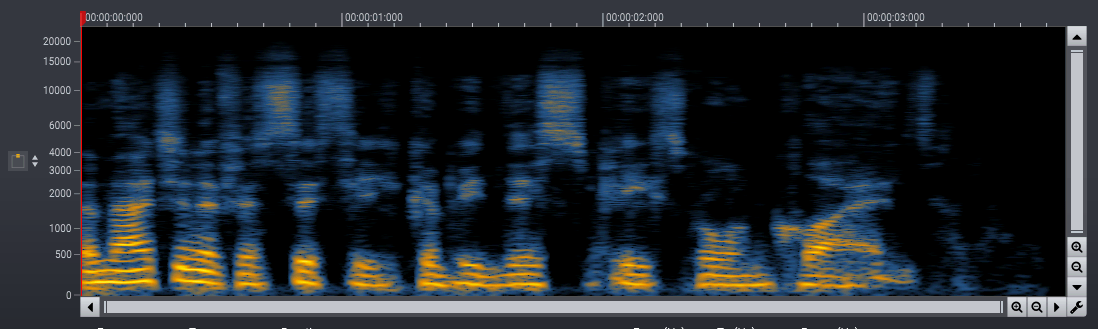
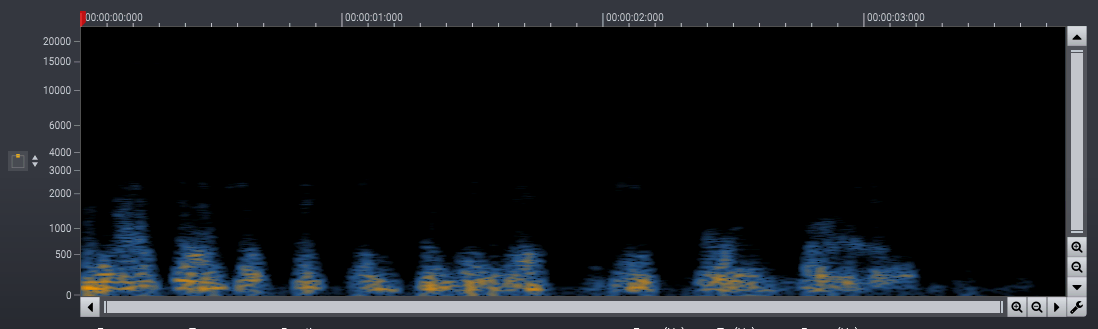
We successfully trained phase-aware models for speech noise reduction. The phase-aware processing improves the perceived audio quality noticeably in the low frequency range. We have processed the introduction sequence of one of our promotional videos recorded at a busy round-about in the middle of Oslo with both phase-aware and real-valued masks in the examples below. The difference between the two processed signals clearly indicates the improvements of the phase-aware processing.

HANCE Audio Engine v2.0.1 is now live - and with it, realtime stem separation made effortless.

Oslo, Norway – June 17th, 2025 – HANCE, a rising innovator in AI-driven audio enhancement, is proud to announce a strategic partnership with Intel....
Acon Digital and HANCE have partnered to launch Remix. This audio plugin operates on the HANCE Audio Engine, a cross-platform library with an easy...

This article summarises the extensive experimental work we have done to develop and build a data training set for Acon Digital’s Extract:Dialogue an...

We partnered with Acon Digital on Extract:Dialogue, which caught the attention of Ellis Rovin at the popular MKBHD YouTube channel, which, at the...

In recent years, with the growth of the artificial intelligence industry, people have shown concern for responsible use, privacy, and data safety. We...