Remix: The Next Step in Real-Time Audio Processing by Acon Digital and HANCE
Acon Digital and HANCE have partnered to launch Remix. This audio plugin operates on the HANCE Audio Engine, a cross-platform library with an easy...

Here at HANCE, we focus on the use of deep learning combined with digital signal processing. Our goal is to create solutions based on state-of-the-art academical insight and make them viable in terms of CPU and latency requirements. Some of the use cases of our technology are:
Stem and vocal separation has been a popular topic in academic research during recent years. Stem separation, dialogue extraction and reverb reduction are closely related problems that can be tackled with the same neural network structure, but with different training sets. We will use the term source separation to describe the general problem. Some source separation methods that deliver state-of-the-art results are:
While these methods provide astonishing results, they are not well suited for real-time processing as they introduce too much latency and have demanding memory and CPU (or GPU) requirements. We will focus on spectrogram-based separation as it is generally less computationally expensive than waveform-based separation and the U-Net structure has proven very effective.
Spectrogram-based methods for source separation typically estimate a separation mask that is multiplied pointwise with the input magnitude spectrogram to form the separated output magnitude spectrogram. For simplicity, the output audio is commonly reconstructed using the phase information from the input spectrogram. By processing magnitude spectrograms this way, we can easily adopt network topologies that have been implemented for image processing by treating the magnitude spectrogram as a gray-scale image.




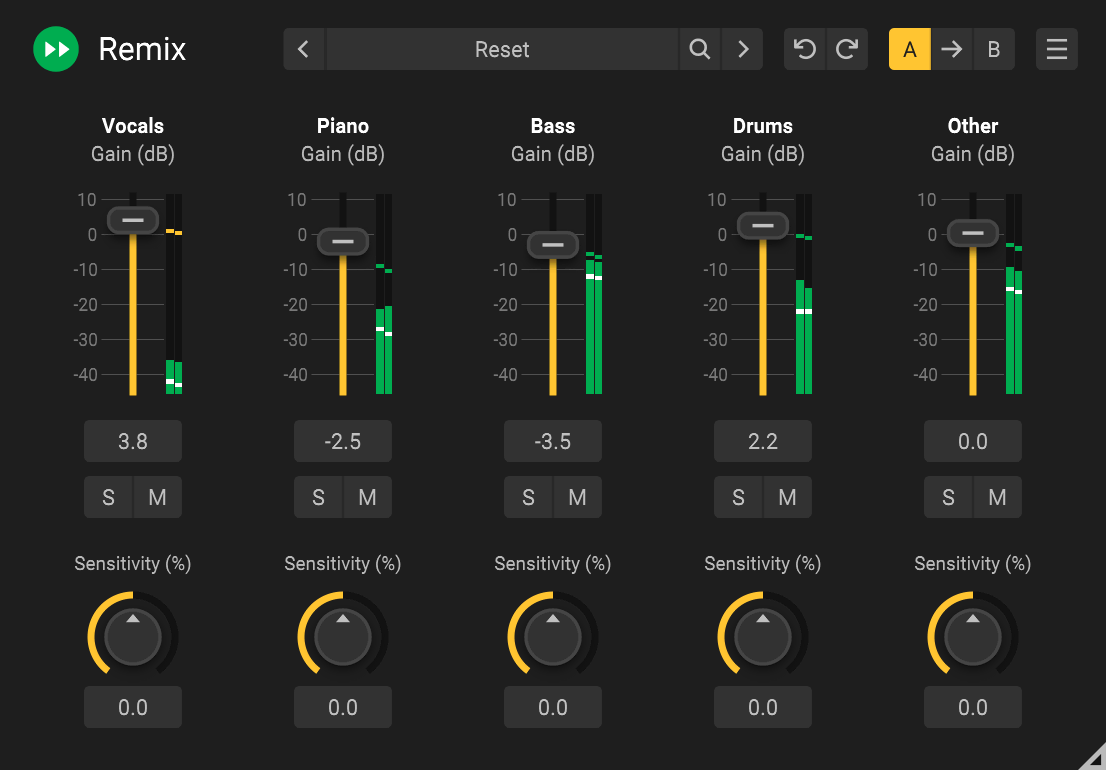
Acon Digital and HANCE have partnered to launch Remix. This audio plugin operates on the HANCE Audio Engine, a cross-platform library with an easy...

This article summarises the extensive experimental work we have done to develop and build a data training set for Acon Digital’s Extract:Dialogue an...
.png)
HANCE 26: The Audio Algorithm Designed for Real-World Complexity

Spectrogram-based methods for source separation using neural networks typically estimate a separation mask that is multiplied pointwise with the...

We partnered with Acon Digital on Extract:Dialogue, which caught the attention of Ellis Rovin at the popular MKBHD YouTube channel, which, at the...